
A Beginner's guide to GANs and their Applications
- Yash upadhyay

- Jun 28, 2020
- 8 min read
Updated: Jul 17, 2020

For long only humans have had the ability to create, the only things Artificial intelligence was good for, was solving problems like Regression, Classification, and Clustering but with the introduction of generative networks, AI researchers were able to make machine generate the content of the same or higher quality compared to their human counterparts.
What are GANs?
Generative Adversarial Networks or GANs are a new type of neural architectures introduced by Ian Goodfellow and other researchers at the University of Montreal, including Yoshua Bengio, in June 2014.GANs have been called the most interesting idea of the decade by Facebook’s AI research director Yann LeCun. GANs are based on the idea of adversarial training. They basically consist of two neural networks that compete against each other. This competitiveness helps them to mimic any distribution of data. Their ability to mimic data makes them just like a Robo artist, as once trained successfully GANs are able to create pieces of art, songs, images, and even videos.
What makes GANs special?
To understand why GANs stand apart, let’s understand the concept of Generative and Discriminative algorithms.
Discriminative algorithms are those whose main aim is to classify the input data, that is if we are given them a set of certain features we will try to figure out to what label or category do those features belong ie discriminative algorithms help us in mapping features to labels.
Generative algorithms, on the other hand, work in a totally different manner than the discriminative algorithms as it tries to create the input data, that is we provide it with a set of features it won’t classify it rather it would try to create a feature that would fit a certain label.
Hence GANs are a special case of generative models that are able to predict features in a much better way due to the adversarial training which explains why they have been so hyped in the AI community.
How does Gan work?
GANs consist of two Neural Network one is called the Generator and the other is called the Discriminator. Generator or the Generative model tries to capture the data distribution and The Discriminator or the Discriminative model estimates the probability that a sample came from the training data rather than G. ie Generator tries to create samples which are identical to the training set and the discriminator tries to differentiate between what the generator is creating and the original sample from the training set. During the training, the generator tries to get better at fooling the discriminator and the discriminator tries to catch the fakes created by the generator hence the training process is called Adversarial training.

Working of GAN
Let’s take an example of generating handwritten digits using a GAN, initially, random noise will be provided to the generator which will try to make a digit, then the discriminator will decide whether the input it is receiving is fake or not. At the beginning of the process, the samples created by the generator won’t be good and will be easily be discarded by the discriminator easily as the training proceeds generator will keep on getting better and better in generating digits meanwhile discriminator will also get better in differentiating, later in the training process, we will start getting fake generated characters which will resemble characters written by humans.
What are GANs used for?
GANs have the power to solve the problems of many industries like healthcare, Automobile fine arts, and many others. In this section, we will learn about some of the use cases of adversarial networks and which GAN architecture is used for that application.
1. Single Image Super-Resolution
We often face problems with low-resolution images as they are not clear, GANs helps us to create High-Resolution images from a single low-resolution image.
For this problem, a GAN called SRGAN is used, we can see how SRGAN is able to create the highest resolution image in the figure below:

SRGAN
Although there are many methods for this the problem of recovering the finer texture details when images are super-resolved at large upscaling factors always remained. SRGAN is the first framework capable of inferring photo-realistic natural images for 4× upscaling factors. It uses a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes the solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images.

The architecture of generator and discriminator
Above are shown the architectures of both the generator and the discriminator. Where k denotes the kernel size, n denotes the number of feature maps s denotes the stride for the convolutional layers. In SRGAN, the generator is trained to create a high-resolution image and the discriminator is trained to differentiate between the original and the high-resolution images.
2. Object Detection
In CVPR 2017, two techniques were proposed which utilized GANs for object detection.
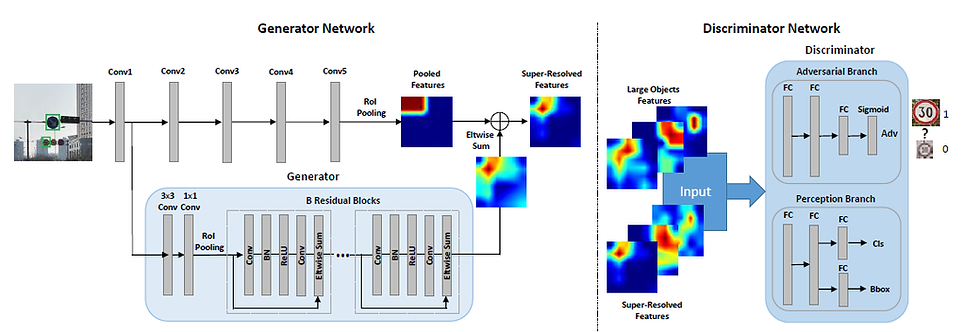
Perceptual GAN
PGANs are specially designed for detecting small objects, as for the previous Object Detection strategies Detecting small objects is notoriously challenging due to their low resolution and noisy representation. PGANs changes the representations of small objects to “super-resolved" ones, achieving similar characteristics as large objects and thus more discriminative for detection. its generator learns to transfer perceived poor representations of the small objects to super-resolved ones that are similar enough to really large objects to fool a competing discriminator. Meanwhile, its discriminator competes with the generator to identify the generated representation and imposes an additional perceptual requirement generated representations of small objects must be beneficial for detection purpose on the generator.
Hard positive generation via the adversary
This technique tries to make the object detector invariant to occlusions and deformations. This technique creates images that have occlusions and deformation. We train a GAN that generates examples that are difficult for the object detector to classify. Before this technique, we were dependent on the dataset hoping that it might have images that were occluded which trained the detector if the examples of occlusions were less it would mean that the detector won’t be able to make the correct classification.

PGAN
3. Text to Image Synthesis
The synthesis of high-quality images from text descriptions is a challenging problem in computer vision. Samples generated by an existing text to image approaches can roughly reflect the meaning of the given descriptions, but they fail to contain necessary details and vivid object parts. The best network for this application is the StackGAN or stacked generative adversarial network which generates generate 256x256 photo-realistic images conditioned on text descriptions.

In stage 1, GAN sketches the primitive shape and colors of the object based on the given text description, yielding low-resolution images
In stage 2, GAN takes the results of stage 1 and text description as input and generates high-resolution images with photo-realistic details. It is able to rectify defects in Stage-I results and add compelling details with the refinement process.
4. Medical Applications
GANs are very useful in the medical field, due to the adversarial training they can be used in for image analysis, anomaly detection or even for the discovery of new drugs. Their ability to synthesize images at unprecedented levels of realism also gives hope that the chronic scarcity of labeled data in the medical field can be resolved with the help of these generative models. Let’s have a look at how gans are used in such situations.
Creating models to detect anomalies relevant to disease progression and treatment monitoring is challenging. Models are typically based on large amounts of annotated data aiming at automating detection. High annotation effort and the limitation to a vocabulary of known markers limit the power of such approaches. Therefore detecting anomalies using supervised learning is feasible and does not provide useful results.

AnoGAN
To counter the above-mentioned challenges we take an unsupervised approach using GANs, AnoGAN which is specifically designed to detect anomalies in the medical field. AnoGAN is a deep convolutional generative adversarial network to learn a manifold of normal anatomical variability, accompanying a novel anomaly scoring scheme based on the mapping from image space to a latent space. Applied to new data, the model labels anomalies, and score image patches indicating their fit into the learned distribution.
5. Generating 3D objects
3D objects generation can find various applications like augmentation of the dataset for 3D object recognition, it can also be used for 3d Face reconstruction which can be used to make facial recognition systems more and more powerful. 3D Generative Adversarial Network or 3D-GAN is used to generate 3D objects from a probabilistic space using volumetric convolutional networks and generative adversarial networks.
Benefits of using 3D-GAN:
The uses of an adversarial criterion, instead of traditional heuristic criteria, enables the generator to capture object structure implicitly and to synthesize high-quality 3D objects
The generator establishes a mapping from a low-dimensional probabilistic space to the space of 3D objects, so that we can sample objects without a reference image or CAD models, and explore the 3D object manifold.
The adversarial discriminator provides a powerful 3D shape descriptor which, learned without supervision, has wide applications in 3D object recognition.

The generator in 3D-GAN. The discriminator usually mirrors the generator
6. High-resolution image synthesis
High-resolution image synthesis is the reverse process of image segmentation. Here we use a semantic map to generate high-resolution images. This is useful for generating videos for training Self Driving cars rather than making videos yourself.

Pix2Pix
Pix2pix is a type of conditional gan. For this task, the objective of the generator G is to translate semantic label maps to realistic-looking images, while the discriminator D aims to distinguish real images from the translated ones. The pix2pix method adopts U-Net as the generator and a patch-based fully convolutional network as the discriminator. The input to the discriminator is a channel-wise concatenation of the semantic label map and the corresponding Image. We can improve the photorealism and resolution by using a coarse-to-fine generator, a multi-scale discriminator architecture, and a robust adversarial learning objective function.
7. Video Generation
Video generation is an extension of image generation which poses a great challenge as we have to consider the temporal dimension of videos during the generation process as Understanding object motions and scene dynamics are the core problems. Due to the limitation of memory and training stability, the generation becomes increasingly challenging with the increase of the resolution/duration of videos. The process of video generation can take place in two ways either we can provide the text as a feature to create a corresponding video or we can provide a video and generate the next possible frames of the video. For carrying out this generation a generative adversarial network with a spatiotemporal convolutional architecture which untangles the scene’s foreground from the background.

Architecture for video generation
They provide a 100-dimensional Gaussian noise input to the network which has two independent streams one for the moving foreground pathway of fractionally-strided spatiotemporal convolutions, and the other is for the static background pathway of fractionally-strided spatial convolutions, both of which up-sample the input data. These two pathways are combined to create the generated video using a mask from the motion pathway.
Competition to GANs
GANs aren’t the only models that belong to the class of generative models other Deep Learning models like Variational Autoencoders and Autoregressive models are also good examples of generative models that are used to mimic the distribution of the data.
These generative algorithms have a different fundamental working, for GANs the training process is like a contest between the generator and the discriminator whereas Variational Autoencoders allow us to formalize the problem of generating training samples in the framework of probabilistic graphical models where we maximize the lower bound on the log-likelihood of the data. In the case of Autoregressive models such as PixelRNN, the training of the network takes place to model the conditional distribution of every individual pixel wrt to the previous pixel.
Comments